
Reinventing team flow within AI uncertainty
Modern LLM tools are providing interesting alternatives to established coding practices. Many software professionals have embraced the new paradigm or embarked on a journey of experimentation, with freelancers and solopreneurs being a significant portion of the first wave.
Structured teams joined a little more slowly, having to balance backlog pressure and agreed deadlines to find the necessary time for significant experiments, in a more conservative corporate environment.
Lately, management has increased pressure, emphasizing the need to introduce AI into software development. In the most extreme scenarios, AI usage is actively promoted with KPIs and incentives for individuals and teams.
I am not convinced that incentives are the best idea, given organizations’ usual tendency to pick the wrong metric (with Tokenmaxxing being a great example). Measuring individual token consumption can lead to inconsistent results in pair programming, while restricting measurement to a specific vendor can artificially narrow the scope of exploration as new approaches are still emerging.
From a purely financial point of view, it may be sensible to run experiments now, while tokens are still underpriced, but gaming the metrics is still one of the most practiced corporate sports.
However, the need to gather information is real. In healthy environments, curiosity itself should be sufficient to drive experimentation with the alternative options enabled by the latest-generation tools.
Put another way, while the long-term impact of LLMs is still under scrutiny, postponing experimentation and failing to build some degree of awareness will be a problem no matter what.
Small isolated experiments won’t be enough
Unlike many technical improvements, LLMs don’t have a specific area of impact. They aren’t limited to a specific step in software development, but they can redefine many steps in traditional software development.
- An agent can support requirement gathering.
- Documentation can be created continuously, from text and code.
- Code can be generated, provided a detailed enough specification of the expected system behavior.
- Agents can serve as sparring partners during coding and design sessions.
- You can write agents to challenge your development plan from many different perspectives.
- Vulnerability checking can be delegated to a specific agent.
- Non-critical specialist contributions can be delegated to AI under given constraints.
… and the list is a lot longer than this. Even worse, new versions are released quickly, making your experiments’ conclusions possibly obsolete.
Please note that I repeatedly used the word “can”: possibilities are almost infinite. But it’s still hard to say which ones will become good ideas. Moreover, AI vendors are trying hard to build lock-in, and current prices won’t be sustainable in the long term. In a scenario where AI would be too expensive to apply everywhere, discerning the most valuable contributions becomes a strategic advantage.
Invalidating assumptions
Unfortunately, small experiments within a consolidated framework may fall short of capturing systemic opportunities. AI agents may be used to generate low-priority artifacts that were traditionally neglected, with a minor impact on the overall flow.
Uncoordinated, individual experiments can eventually make things worse. For example, if you use LLMs in the requirements-gathering phase to write a specification, you may not realize that your clean specification is often taken as is by a developer and turned into a prompt. The handoff can become redundant unless the involved specialists are actively supervising it.
But the combined effect of two isolated experiments may also increase noise and the probability of slop and hallucination.
Pairing and ensemble programming are under pressure, too. Are we training agents to act as partners in a human+AI pair, or do we add AI support to a pair of developers? Can we still call it pairing if every agent is just a mirror of different facets of our coding style? What happens when an entire team is “collaboratively waiting” for a prompt to be completed?
Does estimation still matter? Estimates were already controversial in the past, and a battleground between management and software development teams. Introducing new techniques can neutralize the impact of past experiences. Some tasks, such as integrating third-party services, can be significantly faster. But the possibility of falling into a rabbit hole of agent optimization is often around the corner.
Traditional estimation based on experience and task complexity can be dwarfed by the amount of experimentation your team decides to inject into the selected task, or by the increased number of surprises in your non-deterministic journey.
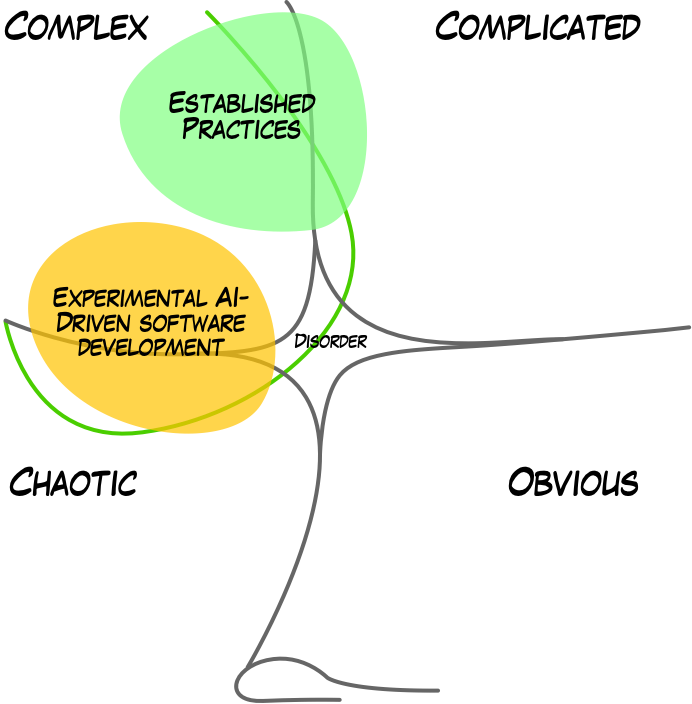
In Cynefin terms, introducing AI tools moves your software development activities into a liminal space between complex and chaotic, especially if you consider the impact on team collaboration. There is no detailed rulebook to refer to, just the need to bring the team into more manageable waters.
Emptied rituals
Processes with established ceremonies are likely to have more dissonance. Those moments were conceived for a different world, a different team size, and a different type of interaction. Do they still matter? Do they still fulfil the original purpose, or is there a better way to achieve the same result?
Meeting duration was an imperfect trade-off between the time needed for doing things and the time needed to agree, reflect, and decide collaboratively. The balance has probably shifted.
Does the current iteration length still make sense? What about the planning meetings? Should we limit them to priority setting?
From Roles to Contributions
When it comes to roles, software development has been continuously struggling with competing attractors. Agile collaboration has often leveraged the concept of swarming, empowering teams to self-organize. But the counterbalancing forces in the organization are strong: salaries are tied to job titles, which often map to a specific role. And with the role comes specific responsibilities.
The early days of “we are all team members” seem far away, with new job titles introduced in the workplace.
When roles are interpreted too strictly, we end up with more handoffs and usually a less effective development process. The friction becomes even more evident during changes or when role-specific duties are attached to KPIs and bonuses.
But AI’s impact is systemic and should be measured at the system level. A good target for measurement maps with skin in the game and feedback loops. A team owning its own features in production is a much better target than a single contributor optimizing the delivery of a temporary artifact.
In times of change, roles aren’t very meaningful; what matters are the contributions that individuals can bring to the emergent collaboration. Roles were defined by skills and seniority for a landscape that has become partially obsolete. In contrast, new AI-related skills may be more closely tied to attitude than to official seniority levels.
For example, the ability to decompose a complex feature into more manageable steps and architectural components is one of the most effective skills in agentic software development, one that cannot be easily delegated. But the current role isn’t a good predictor of this ability. Some POs with a technical background are great at it, while other teams rely more on a technical breakdown of backlog items, leaving product specialists in charge of business priority.
Moreover, the implementation flow differs between business features and architectural improvements, as well as across domains, so finding a perfect recipe will require many experiments, adjustments, and fine-tuning.
Tying improvements to current roles may lead to a defensive stance to protect them. But while roles can be limited to a specific function, individuals can be much more versatile than their job titles suggest. Resetting the roles toward a dynamic contribution-and-learning model can accelerate the transition to a more effective form of collaboration.
Bottlenecks are likely to move
Most of the current hype floats around the idea that AI can speed up coding. But coding may or may not be your system bottleneck. We know from the Theory of Constraints that local optimizations in the wrong place can worsen the system performance. An apparently faster bug-resolution cycle may clog your downstream flow, with multiple pull requests waiting for approval.
Constraints can also move upwards. Product roles can get sucked into a spiral of continuous clarification to ensure LLMs fully understand requirements, or they can start pushing more uncertainties into the development flow because business validation isn’t keeping up with the pace.
Enter continuous experimentation
The most effective way to deal with this level of uncertainty is to embrace it. If you haven’t already, it’s probably time to explicitly increase your team’s experimentation time and make experiments a first-class citizen on your board.
Reset rituals
Rituals and ceremonies as part of standard processes may now serve different needs. A partial switch-off may force your team to rebuild the part that actually matters now. Meetings and ceremonies need to rebuild their legitimacy.
The cadence itself may be revisited. Having more things to juggle in a 2-week iteration seems less interesting than having more focus on a shorter one.
Cadenced checkpoints to align with the experiment’s outcomes and learning may be necessary. A dedicated moment seems better than repurposing the current retrospective format, as needs may conflict.
You should reserve some dedicated time to look for slow signals. AI can offer interesting options and emerging practices, but the cumulative effect of the change may take some time to become visible. New practices can slowly build up technical debt in unexpected places or have weird consequences in the emotional sphere.
Throughput instead of estimation
Estimates with excessive variability quickly become worthless, yet we still need a way to measure the impact of experiments or to tune the number of experiments against strategic deadlines.
Throughput seems to be a more interesting metric that still protects the system’s observability without wasting time in pointless speculation. It also protects you from local optimizations that could clog the system’s bottleneck.
Popcorn Flow can be a good old friend
A good old friend of ours, Claudio Perrone’s Popcorn Flow, is a great format for continuous experimentation initiatives.
In a nutshell, Popcorn Flow defines a kanban-like board that focuses on experiments, lowering the threshold for attempting and committing. The acronym comes from the board states:
- Problem & Observations
- Options
- Possible Experiments
- Committed
- Ongoing
- Review
- Next
The most interesting feature of Popcorn Flow is the reduced threshold for starting an experiment, often to the “why not?” level, and the explicit retrospective moment. If you still don’t know how to make experimentation a key ingredient of your flow in practice, then Popcorn Flow can be a way to play it smoothly and engage a team of explorers.
Assess learning as a team
Changes have consequences, but not for the originators, or not quickly enough to suffer them. A faster software development cycle now may result in a multitude of half-hearted features in our software, harming the design integrity of the whole system. Bad ideas can be discarded faster if paying users aren’t yet using them.
Individual productivity is not a good predictor of team performance. Assessing the impact of the experiments should be a responsibility of those affected by the consequences. This article from David Fowler provides an interesting perspective on how AI can affect team interactions and well-being.
You have a new team member with no accountability and no skin in the game. You will be accountable for the possible consequences of AI’s bad choices. Your experiments should consider this perspective.
Owning the experiments as a team is even more important if you feel threatened by the possibility of becoming redundant. Collaborations cannot be rearranged in isolation.
Repeat the experiments
A single run won’t be enough. Small details - like switching from typing prompts to dictation - will make a lot of difference. Don’t fall into the trap of saying “we tried this and it didn’t work”; assess the outcome, tweak some details, and try again.
New versions of your tools can yield massively different outcomes, either way. Some prompting tricks will stop working or become unnecessary, and some limitations will disappear.
Annoying as it may sound, consider your learning to be ephemeral.
Think out of the prompt
LLM tools are attracting your team towards a chat-based interaction. It may not be the best way to use your time. Consider running experiments away from the LLM interfaces, like talking and sketching more, before entering an LLM chat.
Part of the experiment is about finding a new balance. It won’t happen if you let yourselves be pulled around by new technology.
Observe weak signals
You’re in the middle of a sociotechnical paradigm shift. Things will slowly change in unexpected places. How do you feel at the end of an AI-powered working day? How does everyone feel?
Which other metrics are we not considering? Technology enthusiasts are quick to grasp the possibilities, but we also need to assess the consequences. Establishing precise success criteria before the experiment won’t capture puzzling, unexpected outcomes, unless you’re open to surprises.
United we try
Overall, this all boils down to owning the experimentation initiative as a team. Individual actions remain valid and don’t require any upfront agreement. But the consequences of individual experiments can be an AI-powered version of “it works on my machine”.
Explicitly experimenting as a team will allow you to enter uncharted territories while having a safety net in place.
A curious, well-connected team, reflecting on its own experiments, is a learning juggernaut.
Photo by Jackalope West on Unsplash